Bases de Datos. Introducción
- Una base de datos (BD) es una colección de datos relacionados. Por datos, queremos
decir hechos conocidos que pueden registrarse y tienen un significado implícito.
- Esta es una definición bastante general, por lo que podemos considerar que
la colección de palabras de una página de texto tienen datos relacionados y por
lo tanto constituyen una base de datos.
- Sin embargo, el uso del término base de datos suele ser más restrictivo.
Una BD tiene las siguientes propiedades implícitas:
- Una BD representa algunos aspectos del mundo real, en ocasiones denominado
minimundo o Universo del Discurso (UdD). Los
cambios en el minimundo se reflejan en la BD.
- Una BD es una colección coherente de datos con significados inherentes.
Un conjunto aleatorio de datos no puede considerarse como una BD.
- Una BD se diseña, construye y puebla con datos para un propósito específico.
Está destinada a un grupo de usuarios concreto y tiene algunas aplicaciones
preconcebidas en las cuales están interesados dichos usuarios.
- En suma, una BD tiene:
- alguna fuente de la cual provienen los datos
- algún grado de interacción con los sucesos del mundo real
- una audiencia que está activamente interesada en el contenido de la BD
- Una BD puede tener cualquier tamaño y complejidad
- Una BD puede crearse y mantenerse manualmente o estar informatizada
- Una BD informatizada puede crearse y mantenerse bien mediante un conjunto
de programas de aplicación diseñados específicamente para dicha tarea o bien
mediante un sistema de gestión de bases de datos.
Sistema de Gestión Bases de Datos (SGBD) - (DBMS)
- Software. Conjunto de programas que permiten a los usuarios
crear y mantener una base de datos.
- Software de propósito general que facilita los procesos de definición,
construcción y manipulación de BD para distintas aplicaciones.
- Definición: especificar los tipos de datos, las estructuras
y restricciones para los datos que se van a almacenar en la BD.
- Construcción: proceso de almacenar los datos concretos sobre algún medio
de almacenamiento controlado por el SGBD.
- Manipulación: funciones tales como consultar la BD para recuperar
datos específicos, actualizar la BD para reflejar cambios ocurridos en el minimundo
y generar informes a partir de los datos.
- Denominaremos sistema de base de datos al conjunto formado por
la base de datos más el SGBD.
Archivos convencionales
- Campo: entidad lógica más pequeña que se define como
conjunto de caracteres unidos, tratados como una sola unidad.
- Registro: colección de campos unidos o grupos de datos
que son tratados como una sola unidad.
- Archivo: conjunto de registros que son tratados
como una sola unidad.
- El registro contiene todos los datos necesarios sobre algún objeto.
- Cada registro en un archivo se identifica por medio de una clave de registro.
- Esta clave es un valor presente en cada registro dentro del archivo y este valor
debe ser único para cada registro.
- Los archivos pueden también ser estructurados alrededor de claves secundarias
para diferentes consultas y usos.
Organización de archivos
- Secuencial: los registros se almacenan uno después del otro, en un orden
determinado generalmente por la clave de registro.
- Relativo o Directo: se puede acceder directamente a un registro por su
número relativo de registro (NRR). Para poder acceder a un registro según
una clave que no sea el NRR, se debe aplicar una función de transformación de la
clave en un NRR. Esas funciones son conocidas como funciones de hash.
- Secuencial indexado: se puede acceder directamente a un registro por la clave
de registro
Métodos de acceso
Métodos de acceso según organización
| Organización | Secuencial | Al azar |
|---|
| Secuencial |
Sí |
No |
| Relativa |
Sí |
Sí |
| Secuencial Indexada |
Sí |
Sí |
Características del enfoque de BD
- Naturaleza autodescriptiva de los sistemas de BD: el catálogo
- Separación entre programas y datos, más abstracción de datos
- Soporte de múltiples vistas de datos
- Compartimiento de datos y procesamiento de transacciones multiusuario
Ventajas de usar un SGBD
- Control de redundancia
- Restricción de accesos no autorizados
- Almacenamiento persistente de objetos y estructuras de datos de programas
- Capacidad de realizar inferencias y acciones usando reglas
- Suministro de múltiples interfaces de usuario
- Representación de vínculos complejos entre los datos
- Garantía del cumplimiento de restricciones de integridad
- Suministro de copias de seguridad y recuperación
Implicaciones del enfoque de BD
- Potencial para imponer normas.
- Menor tiempo de creación de aplicaciones.
- Flexibilidad.
- Disponibilidad de información actualizada.
- Economías de escala.
Modelos de datos
- El enfoque de BD proporciona cierto nivel de abstracción de los datos.
Se ocultan ciertos detalles que los usuarios no necesitan conocer.
- Modelo de datos: colección de conceptos que sirven
para describir la estructura de la BD.
- Estructura de la BD: tipos de datos, vínculos y restricciones que
deben cumplir los datos.
- Los modelos de datos pueden contener, además, un conjunto de operaciones básicas
para especificar lecturas y actualizaciones de la BD.
- Cada vez es más común que los modelos de datos incluyan conceptos para especificar
el aspecto dinámico o comportamiento de una aplicación de BD. Esto
permite definir un conjunto de operaciones definidas por el usuario.
Categorías de modelos de datos
- De alto nivel o conceptuales:
- De bajo nivel o físicos:
- De representación o de implantación:
- Modelo de red
- Modelo jerárquico
- Modelo relacional
- Modelo orientado a objetos
- Modelo relacional orientado a objetos
Esquemas, instancias y estado de la BD
- Debemos distinguir entre la descripción de la BD y la BD misma.
- La descripción se conoce como esquema de la BD, se especifica
durante el diseño y no es de esperar que sufra muchas modificaciones.
- En la mayoría de los modelos de datos se utilizan ciertas convenciones
para representar los esquemas en forma de diagramas. La representación de un
esquema se llama diagrama del esquema.
- Un diagrama del esquema visualiza únicamente algunos aspectos del esquema
tales como los nombres de los tipos de registro y de los elementos de datos
y de algunos tipos de restricciones. Otros aspectos no aparecen reflejados.
- Los datos reales de la BD pueden cambiar con mucha frecuencia. Los datos
que la BD tiene en un determinado momento se donominan estado de la BD
o instantánea. También se le denomina conjunto actual de ocurrencias
o instancias de la BD.
- La distinción entre esquema y estado es muy importante. Cuando definimos una BD
sólo especificamos su esquema. En ese momento su estado es el estado vacío, sin datos.
- Cuando poblamos o cargamos los datos por primera vez, la BD pasa
al estado inicial.
- De ahí en adelante, cada operación de actualización en la BD dará lugar a un nuevo estado.
- El SGBD se ocupa de que cada estado sean un estado válido.
- El SGBD almacena descripciones de los elementos del esquema y las restricciones.
Estas descripciones reciben el nombre de meta-datos y son almacenadas
en el catálogo de la BD.
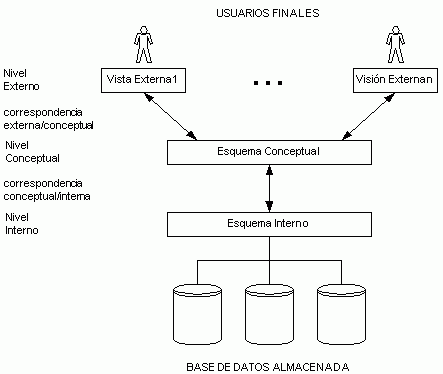
Arquitectura de tres esquemas
- Objetivo: separar las aplicaciones del usuario y la base de datos física
- Tres niveles:
- El nivel interno tiene un esquema interno,
que describe la estructura física
de almacenamiento de la BD.
- El nivel conceptual tiene un esquema conceptual,
que describe la estructura completa de la BD para una comunidad de usuarios.
El esquema conceptual oculta los detalles de las estructuras físicas de almacenamiento
y se concentra en describir entidades, tipos de datos, vínculos, operaciones de los
usuarios y restricciones.
- El nivel externo o de vistas incluye
varios esquemas externos o vistas de usuario.
Cada esquema externo describe la parte de la BD que interesa a un grupo de usuarios
determinado, y oculta a ese grupo el resto de la BD.
Arquitectura de tres esquemas. Diagrama
Independencia de datos
Puede definirse como la capacidad de modificar el esquema en un nivel del
sistema de base de datos, sin tener que modificar el esquema del nivel
inmediato superior.
Se pueden definir dos tipos de independencia:
- La independencia lógica de los datos es la capacidad de
modificar el esquema conceptual sin tener que alterar los esquemas externos
ni los programas de aplicación.
- La independencia física de los datos es la capacidad de
modificar el esquema interno sin tener que alterar el esquema conceptual o los externos.
Lenguajes del SGBD
- Lenguaje de definición de datos (LDD, en inglés DDL):
para especificar el esquema conceptual.
- Lenguaje de definición de almacenamiento (LDA, en inglés SDL):
para especificar el esquema interno.
- Lenguaje de definición de vistas (LDV, en inglés VDL):
para especificar el esquema interno.
- Lenguaje de manipulación de datos (LMD, en inglés DML):
requerido para manipular la información.
- Lo más común es la inserción, eliminación y modificación de datos.
- Existen LMD de alto nivel y de bajo nivel.
- Los LMD de alto nivel utilizados en forma interactiva e independiente se denominan
lenguajes de consulta.
Modelado de datos
Construcción del Modelo de Implantación
- Las entidades del ME/R serán relaciones (tablas),
considerando como excepciones aquellas entidades que representan conjuntos constantes conocidos,
como meses del año, días de la semana, fechas, etc.
- El atributo determinante de la entidad, será la clave primaria.
- También serán relaciones (tablas):
- Las relaciones del ME/R, binarias, de clase N-N
- La clave, en este caso, la forman los atributos determinantes de las entidades que participan en la relación.
Cada uno de estos atributos determinantes, es, a su vez, clave foránea.
- Las relaciones n-arias del ME/R, en los casos en que n > 2
- La clave, en este caso, la forman los atributos determinantes de las entidades que participan en la relación,
pero se excluyen aquellos que pertenezcan a entidades con cardinalidad 1.
Modelo de Implantación: relaciones N-1
- En las relaciones binarias de clase N-1 (1-N), la entidad de cardinalidad N, absorbe
los atributos de la entidad de cardinalidad 1, más los atributos de la relación
- El atributo determinante de la entidad de cardinalidad 1, será clave foránea en la tabla creada.
Modelo de Implantación: categorías
- Las categorías pueden terminar en:
- Relaciones (tablas), cuando tienen atributos propios, o bien están relacionadas con otra entidad.
La clave primaria es el atributo determinante de la entidad padre.
- Atributos (columnas) en la relación (tabla) resultante de la entidad padre. Generalmente es así, cuando la categorización no tiene atributos propios,
o bien no está relacionada con otra entidad.
Conceptos del Modelo Relacional
- El Modelo Relacional representa la base de datos como una colección de relaciones.
- Una relación se asemeja a una tabla de valores, o en cierta medida a un archivo
"plano" de registros.
- Cada fila de la tabla representa un hecho que normalmente se corresponde con una entidad o vínculo
del mundo real.
- El nombre de la tabla y los de las columnas ayudan a interpretar el significado de los
valores que están en cada fila.
- En la terminología formal del modelo relacional, una fila se denomina tupla,
un encabezado de columa es un atributo y la tabla se denomina relación.
- El tipo de dato que describe los tipos de valores que pueden aparecer en cada
columna se llama dominio.
Dominio
- Un dominio D es un conjunto de valores atómicos.
Por atómico queremos decir que cada valor del dominio
es indivisible en lo tocante al modelo relacional.
- Ejemplos:
- Números_Telefónicos_UY: el conjunto de los números telefónicos de ocho
dígitos.
- Nombres: el conjunto de los nombres de personas.
- Promedios_de_notas: valores posibles de promedios de notas
calculados, cada uno debe ser un valor entre 0 y 12.
- También debe especificarse un tipo de datos o formato
para cada dominio. Por ejemplo, se puede declarar el tipo de datos del dominio
Números_Telefónicos_UY como una cadena de caracteres de la forma dddd-dddd,
donde cada d es un dígito numérico decimal.
- También puede indicarse información adicional para interpretar los valores de un dominio.
Por ejemplo: en un dominio numérico como Pesos_de_personas deberá especificar las
unidades de medición: libras o kilos.
Esquema de relación
- Un esquema de relación R denotado por
R(A1, A2, ..., An), se compone de un
nombre de relación
y una lista de atributos A1, A2, ..., An.
- Cada atributo Ai, es el nombre de un papel desempeñado
por algún dominio D en el esquema R. Se dice que D es el dominio
de Ai y se denota como dom(Ai).
- Un esquema de relación sirve para describir una relación; R
es el nombre de la relación.
- El grado de la relación es el número de atributos, n, de su esquema de relación.
- El siguiente es un esquema de relación para una relación de grado 7, que
describe estudiantes universitarios:
-
Estudiante(Nombre, CI, Teléfono, Domicilio, Celular, FchNacimiento, PromedioNotas)
Ejemplar de relación
- Una relación (o ejemplar de relación)
r del esquema de relación
R(A1, A2, ..., An),
denotado también por r(R), es un conjunto de n_tuplas
r{t1, t2, ..., tm}.
- Cada n_tupla t es una lista de n valores
t = <v1, v2, ..., vn>,
donde cada valor vi, 1 ≤ i ≤ n, es un elemento de dom(Ai) o bien
es un valor nulo especial.
- También se usan los términos intensión de una relación para el esquema
R
y extensión (o estado) de una relación para un ejemplar
de relación r(R).
Restricciones del Modelo Relacional
- Restricciones de Dominio
- Restricciones de Clave
- Restricciones de Integridad de Entidad
- Restricciones de Integridad Referencial
- Otros tipos de restricciones, llamadas dependencia de los datos
que incluyen las llamadas dependencias funcionales y dependencias multivaluadas
se aplican fundamentalmente en el diseño a través de la normalización.
Restricciones de Dominio
- Especifican que el valor de cada atributo A debe ser un valor
atómico del dominio dom(A) para ese atributo.
- Nos referimos a tipos como entero, punto flotante, caracteres, y también a intervalos y
tipos enumerados
Restricciones en la clave y restricciones sobre nulos
- Una relación se define como un conjunto de tuplas. Por definición todos los elementos
de un conjunto deben ser distintos; por lo tanto, todas las tuplas de una relación deben ser
distintas.
- Significa que no puede haber dos tuplas que tengan la misma combinación de valores para
todos sus atributos.
- Por lo regular existen otros subconjuntos de atributos de un esquema de relación
R con la propiedad de que no debe haber dos tuplas en un ejemplar de relación
r de R con la misma combinación de valores para estos atributos.
- Supongamos que denotamos un subconjunto así de atributos con SC; entonces, para
dos tuplas distintas cualesquiera t1 y t2
en un estado de relación r de R tenemos la siguiente restricción:
Superclave y Clave
- Todo conjunto de atributos SC se denomina superclave del
esquema de relación R.
- Una superclave SC especifica una restricción de unicidad que significa
que dos tuplas distintas en un estado r de R no pueden tener el mismo valor
para SC.
- Toda relación tiene, por lo menos, una superclave: el conjunto de todos sus atributos.
- Sin embargo, una superclave puede tener atributos redundantes, así que un concepto mucho
más útil es el de clave que carece de redundancia.
- Una clave K de un esquema de relación R,
es una superclave de R con la propiedad adicional de que la eliminación de
cualquier atributo A de K deja un conjunto de atributos K'
que no es una superclave de R.
- Por lo tanto, una clave es una superclave mínima, es decir,
una superclave a la que no podemos quitarle atributos sin que deje de cumplir la
restricción de unicidad.
- En general, un esquema de relación puede tener más de una clave. En tal caso, cada
una de ellas se denomina clave candidata.
- Es habitual designar a una de las claves candidatas como clave primaria
de la relación. Esta es la clave candidata cuyos valores sirven para identificar las tuplas
de la relación. Se adopta la convención de subrayar los atributos que forman la clave primaria
de un esquema de relación.
- Cuando existen varias claves candidatas, la elección de una para funcionar como
clave primaria es arbitraria; sin embargo, es mejor elegir una clave primaria con un
solo atributo o un número reducido de atributos.
- Hay otra restricción sobre los atributos que especifica si se permiten o no valores nulos.
Por ejemplo, si toda tupla de ESTUDIANTE debe tener un valor válido y no nulo para
el atributo Apellido, entonces el Apellido del ESTUDIANTE tiene
la restricción de ser NO NULO (NOT NULL).
BDR y esquemas de BD
- Si bien hemos visto relaciones y esquemas de relaciones individuales, una BDR
suele tener muchas relaciones y en estas las tuplas están relacionadas de diversas
maneras.
- Un esquema de base de datos relacional S es un conjunto
de esquemas de relaciones
S = {R1, R2,..., Rm}
y un conjunto de restricciones de integridad RI.
- Un estado o instancia de base de datos relacional BD de
S es un conjunto de estados de relaciones
BD = {r1, r2,..., rm}
tal que cada ri es un estado de R y tal que los estados
de relaciones ri satisfacen las restricciones de integridad
especificadas en RI.
- Cada SGBD relacional debe tener un LDD para definir el esquema de una BDR. La mayoría
utiliza el SQL.
- Las restricciones de integridad se especifican en el esquema de una BD y se deben
cumplir en todos los estados de ese esquema. Además de las restricciones de dominio
y de clave, hay otros dos tipos de restricciones que se consideran parte del modelo
relacional:
- Integridad de entidades
- Integridad referencial
Integridad de entidades, integridad referencial, claves foráneas
- La restricción de integridad de entidades, establece que ningún valor
de clave primaria puede ser nulo. Esto es porque el valor de la clave primaria
sirve para identificar las tuplas individuales en una relación:
el que una clave primaria tenga nulos implica que no podemos identificar
algunas tuplas.
- Las restricciones de clave y de integridad de entidades se especifican sobre
relaciones individuales. La restricción de integridad referencial se
especifica entre dos relaciones y sirve para mantener la consistencia entre tuplas
de las dos relaciones.
- En términos sencillos, la restricción de integridad referencial establece que
una tupla en una relación que haga referencia a otra relación deberá referirse a
una tupla existente en esa relación.
- Una definición formal exige definir primeramente el concepto de clave foránea
(foreign key).
- Un conjunto de atributos CF en el esquema de relación R1
es una clave foránea de R1, si satisface las dos reglas
siguientes:
- Los atributos de CF tienen el mismo dominio que los atributos de la clave
primaria CP de otro esquema de relación R2;
se dice que los atributos CF hacen referencia o se refieren
a la relación R2.
- Un valor de CF en una tupla t1 del estado actual
r1(R1) ocurre como valor de CP en alguna tupla
t2 del estado actual r2(R2)
o bien es nulo.
- En el primer caso, tenemos que
t1[CF] = t2[CP], y decimos que la tupla
t1 hace referencia o se refiere
a la tupla t2.
- R1 se denomina relación referenciante y
R2 es la relación referenciada.
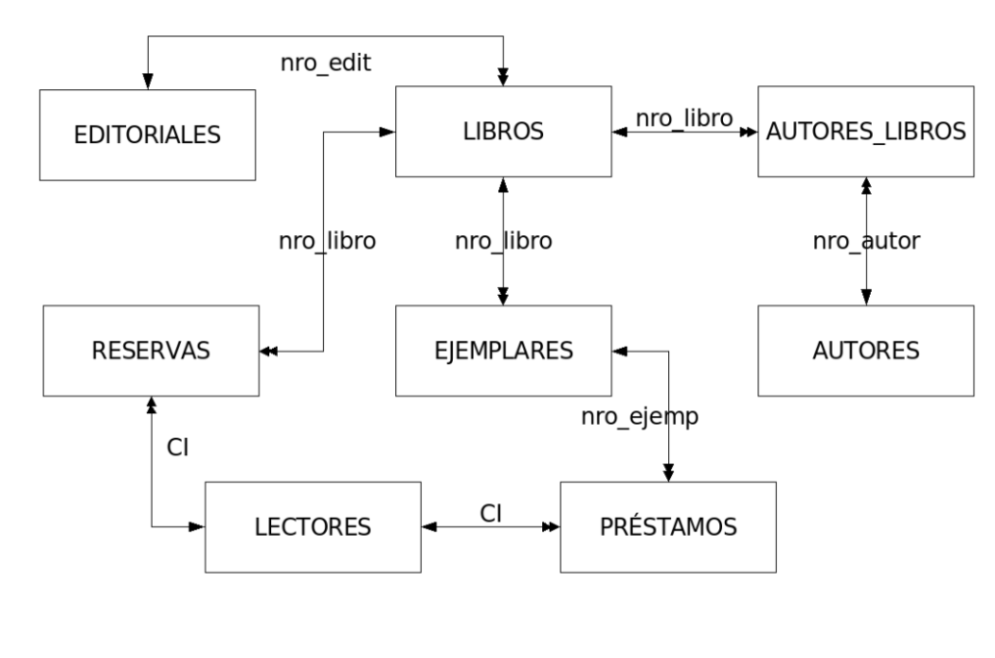
Relaciones de una aplicación de Biblioteca
Las claves primarias (PK) se subrayan.
Las claves foráneas (FK) se escriben en bastardilla.
- LECTORES (
CI,
APELLIDOS,
NOMBRES,
DOMICILIO,
TELÉFONO
)
- LIBROS (
NRO_LIBRO,
TÍTULO,
EDICIÓN,
NRO_EDIT,
AÑO,
ISBN
)
- EJEMPLARES (
NRO_EJEMP,
NRO_LIBRO,
FCH_COMPRA,
USO,
ESTADO
)
- AUTORES (
NRO_AUTOR,
NOMBRE,
NACIONALIDAD
)
- AUTORES_LIBROS (
NRO_LIBRO,
NRO_AUTOR,
PARTICIPACIÓN
)
- EDITORIALES (
NRO_EDIT,
NOMBRE
)
- RESERVAS (
CI,
NRO_LIBRO,
FCH_RESERVA,
ESTADO
)
- PRÉSTAMOS (
CI,
NRO_EJEMP,
FCH_PRÉSTAMO,
FCH_VENCIMIENTO,
FCH_DEVOLUCIÓN
)
Diagrama de Acceso de Datos de la aplicación de Biblioteca
Álgebra relacional. Operaciones básicas
- Además de definir la estructura y restricciones de la base de datos,
un modelo de datos debe incluir
un conjunto de operaciones para manipular los datos.
- El álgebra relacional está formada por un
conjunto básico de operaciones del modelo relacional.
- Estas operaciones permiten al usuario especificar las peticiones básicas de recuperación.
El resultado de una recuperación es una nueva relación
que se ha formado a partir de una o más relaciones.
- Por tanto, las operaciones del álgebra relacional
producen nuevas relaciones que podrán manipularse en el futuro, utilizando operaciones
de la misma álgebra.
- Una secuencia de operaciones del álgebra relacional forma una
expresión de álgebra relacional cuyo resultado será también una relación.
- Las operaciones del álgebra relacional suelen clasificarse en dos grupos.
- Uno contiene el conjunto de operaciones de la teoría matemática de conjuntos:
es posible aplicarlas porque las relaciones se definen como conjuntos de tuplas.
Entre las operaciones de conjuntos están la UNIÓN,
la INTERSECCIÓN, la DIFERENCIA y el PRODUCTO CARTESIANO.
- El otro grupo consiste en operaciones creadas específicamente para base de datos relacionales:
incluye SELECCIONAR, PROYECTAR, y REUNIÓN, entre otras.
La operación SELECCIONAR
- Sirve para seleccionar un subconjunto de las tuplas de una relación
que satisfacen una condición de selección.
- Se puede considerar como un filtro que mantiene únicamente aquellas tuplas que
satisfacen una condición de cualificación.
- Por ejemplo, para seleccionar las tuplas de EJEMPLARES que son para uso en sala o
los que están datos de baja, podemos especificar individualmente cada una de estas
dos condiciones con la operación SELECCIONAR, de la siguiente manera:
- σUSO = S (EJEMPLARES)
- σESTADO = B (EJEMPLARES)
- En general se denota la operación SELECCIONAR con
- σ<condición de selección> (R)
- La relación resultante tiene los mismos atributos que R.
- La expresión booleana especificada en <condición de selección> se compone
de una o más cláusulas de la forma:
-
<nombre de atributo>
<operador de comparación>
<valor constante>
-
<nombre de atributo>
<operador de comparación>
<nombre de atributo>
La operación PROYECTAR
- Si pensamos en una relación como una tabla, la operación SELECCIONAR
selecciona algunas filas de la tabla y desecha otras.
- La operación PROYECTAR, en cambio, selecciona ciertas
columnas de la tabla y desecha las demás.
- Si sólo nos interesan ciertos atributos de la relación,
usamos la operación PROYECTAR para "proyectar" la relación sobre
esos atributos únicamente.
- Por ejemplo, si queremos hacer una lista con el apellido, el nombre y el teléfono de
todos los lectores, usamos la siguiente operación proyectar:
- πAPELLIDOS, NOMBRES, TELÉFONO (LECTORES)
- La forma general de la operación PROYECTAR es:
- π<lista de atributos> (R)
- El resultado contiene únicamente los atributos especificados en <lista de atributos>
y en el mismo orden en que aparecen en la lista. Por ello el grado
es igual al número de atributos en <lista de atributos>.
- Si la lista de atributos sólo contiene atributos no clave de R, es probable
que aparezcan tuplas repetidas en el resultado. La operación PROYECTAR elimina
cualquier tupla repetida y por lo tanto el resultado es una relación válida.
Secuencia de operaciones y la operación RENOMBRAR
- En general es posible que se desee aplicar varias operaciones del álgebra relacional
una tras otra.
- Para eso es posible escribir las operaciones en una sola expresión del
álgebra relacional anidándolas, o bien aplicar una operación cada vez y crear
relaciones de resultados intermedios.
- Por ejemplo, si queremos título y número ISBN de los libros editados en el 2010, podemos
escribir una sola expresión como sigue:
-
πTÍTULO, ISBN (
σAÑO = 2010 (LIBROS))
- Como alternativa, se puede mostrar explícitamente la secuencia de operaciones,
dando un nombre a cada una de la relaciones intermedias:
-
LIBROS_2010 ← σAÑO = 2010 (LIBROS)
-
RESULTADO ← πTÍTULO, ISBN (LIBROS_2010)
- A menudo es más sencillo descomponer una secuencia compleja
de operaciones especificando relaciones de resultados intermedios
que escribir una sola expresión del álgebra relacional.
- También podemos usar esta técnica para renombrar los atributos
de las relaciones intermedias y de la resultante. Esto puede ser útil cuando se trata de operaciones
más complejas como UNIÓN o REUNIÓN, según se verá más adelante.
- Para renombrar los atributos de una relación, bastará con que incluyamos una
lista con los nuevos nombres entre paréntesis:
-
LIBROS_2010 ← σAÑO = 2010 (LIBROS)
-
R (TÍTULO_DEL_LIBRO, NÚMERO_ISBN) ← πTÍTULO, ISBN (LIBROS_2010)
- La opreación RENOMBRAR cuando se aplica a una relación de
R de grado n se denota por:
-
ρS(B1, B2, ..., Bn) (R) o
ρS (R) o
ρ(B1, B2, ..., Bn) (R)
Operaciones de la teoría de conjuntos
- El siguiente grupo de operaciones del álgebra relacional son las operaciones matemáticas
estándar de conjuntos.
- Por ejemplo, para obtener los números de cédula de los lectores que hayan retirado
o reservado libros en el año 2010, podemos utilizar la operación UNION como sigue:
-
RESERVAS_2010 ← σ FCH_RESERVA ≥ 01/01/2010 (RESERVAS)
-
CI_RESERVAS_2010 ← π CI (RESERVAS_2010)
-
PRÉSTAMOS_2010 ← σ FCH_PRÉSTAMO ≥ 01/01/2010 (PRÉSTAMOS)
-
CI_PRÉSTAMOS_2010 ← π CI (PRÉSTAMOS_2010)
-
RESULTADO ← CI_RESERVAS_2010 ∪ CI_PRÉSTAMOS_2010
Otras operaciones de la teoría de conjuntos
- Se utilizan varias operaciones de la teoría de conjuntos para combinar de
diversas maneras los elementos de dos conjuntos, entre ellas, UNIÓN,
INTERSECCIÓN Y DIFERENCIA.
- Estas operaciones son binarias; es decir, se aplican a dos conjuntos.
- Al adaptar estas operaciones a las bases de datos relacionales, las dos relaciones
a las que se aplique cualquiera de las tres operaciones anteriores deberán tener
el mismo tipo de tuplas; esta condición se denomina compatibilidad con la unión.
- Se dice que dos relaciones
R(A1, A2, ..., An) y
S(B1, B2, ..., Bn) son
compatibles con la unión si tienen grado n
y si dom(Ai) = dom(Bi) para 1 ≤ i ≤ n.
- Esto significa que las dos relaciones tienen el mismo número de atributos y que
cada par de atributos correspondientes tienen el mismo dominio.
Unión, intersección y Diferencia
- Podemos definir las tres operaciones UNIÓN, INTERSECCIÓN
y DIFERENCIA para dos relaciones
compatibles con la unión R y S, como sigue:
- UNIÓN: el resultado de la operación, denotado por R ∪ S,
es una relación que incluye todas las tuplas que están en R o en S o en ambas.
Las tuplas repetidas se eliminan.
- INTERSECCIÓN: el resultado de esta operación, denotado por R ∩ S
es una relación que incluye las tuplas que están tanto en R como en S.
- DIFERENCIA DE CONJUNTOS: el resultado de esta operación, denotado por
R — S, es una relación
que incluye todas las tuplas que están en R pero no en S.
-
Adoptaremos la convención de que la relación resultante tiene los mismos nombres
de atributos que la primera relación R.
- Tanto la unión como la intersección son operaciones conmutativas, es decir:
-
R ∪ S = S ∪ R
-
R ∩ S = S ∩ R
- Tanto la unión como la intersección pueden tratarse como operación n-arias aplicables
a cualquier número de relaciones, y las dos son operaciones asociativas, es decir:
-
R ∪ (S ∪ T) = (R ∪ S) ∪ T
-
(R ∩ S) ∩ T = R ∩ (S ∩ T)
- La operación diferencia no es conmutativa; es decir, en general,
Producto cartesiano
- Operación también conocida como PRODUCTO CRUZADO o REUNIÓN CRUZADA,
que se denota por ×.
- También esta es una operación binaria, pero las relaciones a las que se aplica no tienen
que ser compatibles con la unión.
- Esta operación sirve para combinar tuplas de dos relaciones de forma combinatorial.
En general, el resultado de
R(A1, A2, ..., An) ×
S(B1, B2, ..., Bm)
es una relación Q
con n + m atributos
Q(A1, A2, ..., An,
B1, B2, ..., Bm), en ese orden.
- La relación resultante Q tiene una tupla por cada combinación de tuplas:
una de R y una de S. Por tanto, si R tiene nR
tuplas y S tiene nS tuplas, R × S tendrá
nR*nS tuplas.
- La operación aplicada por sí misma generalmente carece de significado. Es útil
cuando es seguida de una selección que empareja valores de atributos procedentes
de las relaciones componentes.
Producto cartesiano: un ejemplo
- Ejemplo: supongamos que queremos obtener nombre, apellido y número de teléfono
de los lectores que hayan retirado
o reservado libros en el año 2010. Procedemos como sigue:
-
RESERVAS_2010 ← σ FCH_RESERVA ≥ '01/01/2010' Y FCH_RESERVA ≤ '31/12/2010' (RESERVAS)
-
CI_RESERVAS_2010(CIR) ← π CI (RESERVAS_2010)
-
PRÉSTAMOS_2010 ← σ FCH_PRÉSTAMO ≥ '01/01/2010' Y FCH_PRÉSTAMO ≤ '31/12/2010' (PRÉSTAMOS)
-
CI_PRÉSTAMOS_2010(CIP) ← π CI (PRÉSTAMOS_2010)
-
CI_PREST_RES_2010 ← CI_RESERVAS_2010 ∪ CI_PRÉSTAMOS_2010
-
LECTORES_PREST_RES_2010 ← CI_PREST_RES_2010 × LECTORES
-
LECTORES_PREST_RES_2010_REALES
← σ
CIP = CIR
(LECTORES_PREST_RES_2010)
-
RESULTADO
← π
nombres, apellidos, teléfono
(LECTORES_PREST_RES_2010_REALES)
La operación Reunión (JOIN)
- Como esta secuencia de producto cartesiano seguido de selección se utiliza con mucha frecuencia
para identificar tuplas relacionadas de dos relaciones, se creó una operación especial llamada
REUNIÓN, con el fin de especificar esta secuencia en una sola operación.
- La operación REUNIÓN, denotada por
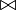 sirve para combinar
tuplas relacionadas de dos relaciones en una sola tupla.
sirve para combinar
tuplas relacionadas de dos relaciones en una sola tupla.
- Ejemplo: supongamos que es necesario obtener una lista de atrasados al 21 de abril de 2010,
con apellido, nombre y teléfono.
-
ATRASOS ← σ FCH_DEVOLUCIÓN NULA Y FCH_VENCIMIENTO < '21/04/2010' (PRÉSTAMOS)
-
LECTORES_ATRASADOS ← ATRASOS LECTORES
- La forma general de una operación reunión con dos relaciones
R(A1, A2, ..., An) y
S(B1, B2, ..., Bm) es:
-
R <condición de reunión> S
- El resultado de la REUNIÓN es una relación Q con n + m atributos
Q(A1, A2, ..., An,
B1, B2, ..., Bm) en ese orden; Q tiene
una tupla por cada combinación de tuplas (una de R y una de S) siempre que la combinación
satisfaga la condición de reunión.
- Esta es la principal diferencia entre el PRODUCTO CARTESIANO y la REUNIÓN: en la REUNIÓN, sólo
aparecen en el resultado combinaciones de tuplas que satisfagan la condición de reunión; en cambio
en el PRODUCTO CARTESIANO, todas las combinaciones de tuplas se incluyen en el resultado.
- La condición de reunión se especifica en términos de los atributos de las dos relaciones,
R y S,
y se evalúa para cada combinación de tuplas. Cada combinación de tuplas para la cual la evaluación
de la condición con los valores de los atributos produzca el resultado "verdadero", se incluirá
en la relación resultante, Q, como una sola tupla.
- Una condición de reunión tiene la forma:
-
<condición> Y <condición> Y ... Y <condición>
Reunión Natural
-
La definición estándar de REUNIÓN NATURAL,
denotada por ∗,
exige que los dos atributos
de reunión (o cada par de atributos de reunión) rengan el mismo nombre en las dos relaciones. Si
no es así, pimero se aplica una operación de cambio de nombre.
-
En general, la REUNIÓN NATURAL se realiza igualando todos los pares
de atributos que tienen el mismo nombre
en las dos relaciones. Puede haber una lista de abritutos de reunión de cada relación, y cada par
correspondiente debe tener el mismo nombre.
-
Una definición más general, pero no estándar, de reunión natural es
-
Q ← R ∗ (<listai1>), (<lista2>) S
- En este caso <lista1> especifica una lista de i
atributos de R y <lista2>
especifica una lista de i atributos de S.
- Las listas sirven para formar condiciones de compararción de igualdad entre
pares de atributos correspondientes;
después se encadenan las condiciones con el operador Y.
Sólo la lista que corresponde a los atributos de la primera relación R,
<lista1>, se conserva en el resultado Q.
- Cabe señalar que si ninguna combinación de tuplas satisface la condición de REUNIÓN
R <condición de reunión> S,
el resultado es una relación vacía con cero tuplas.
- En general, si R tiene nR tuplas y S
tiene nS
tuplas, el resultado de una operación de reunión tendrá entre cero
y nR*nS tuplas.
- Si no hay condición, todas las combinaciones de tuplas califican y la REUNIÓN
se convierte en un PRODUCTO CARTESIANO.
- La operación de reunión se utiliza para combinar datos de varias relaciones de forma que la
información relacionada se pueda representar en una única tabla. Nótese que a veces se puede
especificar una reunión de una relación consigo misma.
Reunión Externa y Unión Externa
-
Las operaciones de REUNIÓN antes descritas seleccionan tuplas que satisfacen la condición
de reunión.
- Por ejemplo, con una operación de reunión natural R ∗ S, sólo las tuplas
de R que tienen tuplas
coincidentes en S, y vice versa, aparecen en el resultado.
Por tanto, las tuplas sin una «tupla relacionada»
se eliminan en el resultado.
Las tuplas que tienen nulo en el atributo de reunión también se eliminan.
- Podemos usar un conjunto de operaciones llamadas REUNIONES EXTERNAS,
cuando queramos conservar
en el resultado todas las tuplas que estén en R, o en S,
o en ambas, ya sea que tengan o no tuplas coincidentes en la otra relación.
-
Por ejemplo, asumiendo que no todo libro tiene autor, supongamos que es necesario obtener todos los
números de libro con sus autores correspondientes. En ese caso, podemos aplicar la operación
REUNIÓN EXTERNA IZQUIERDA, denotada por
]Χ|.
-
TEMP ← AUTORES_LIBROS
]Χ|.
AUTORES
- La operación conserva todas las tuplas de la primera relación (la de la izquierda).
Si no se encuentra una coincidente en la otra relación, los atributos correspondientes de
AUTORES se «rellenan» con valores nulos.
- De modo similar la REUNIÓN EXTERNA DERECHA denotada por
|Χ[,
conserva en el resultado de R
|Χ[ S
todas las tuplas de la segunda relación S (la de la derecha).
- Una tercera operación, la REUNIÓN EXTERNA COMPLETA denotada por
]Χ[,
conserva todas las tuplas de ambas relaciones, cuando no se encuentran tuplas
coincidentes, rellenándolas con valores nulos si es necesario.
Unión Externa
- La operación UNIÓN EXTERNA se creó para efectuar la
unión de dos tuplas de dos
relaciones que no son compatibles con la unión.
- Esta operacion efectuará la unión de tuplas de dos relaciones que sean
parcialmente compatibles, lo que significa que sólo algunos
de sus atributos son compatibles con la
unión. Se espera que la lista de atributos compatibles incluya la clave de ambas
relaciones.
- Las tuplas de las relaciones componentes con la misma clave,
se representan sólo una vez en el resultado y tienen valores para todos los
atributos del resultado.
- Los atributos de cada relación que no son compatibles con la unión se mantienen
en el resultado, y las tuplas que no tienen valores para dichos atributos se
rellenan con valores nulos.
SQL
- El lenguaje SQL es posiblemente una de las razones del
éxito de las bases de datos relacionales en el mundo comercial.
- Es un lenguaje global: cuenta con sentencias de definición, consulta y
actualización de datos.
- Es tanto LMD como LDD.
- Cuenta con recursos como para definir vistas de la BD, para especificar
seguridad y privilegios, para definir restricciones de integridad, y para
especificar controles de transacciones.
- Tiene reglas como para insertar sentencias SQL en lenguajes de programación
como C y otros.
- SQL emplea los términos tabla,
fila y columna, en lugar de relación, tupla y atributo.
- Para definición de datos: CREATE, ALTER y DROP.
Create Table
- Instrucción para crear una nueva tabla, dándole un nombre y especificando
atributos y restricciones.
- Es posible especificar restricciones de clave, de integridad de entidad y
de integridad referencial. Esto se hace tras declarar los atributos (columnas)
o puede realizarse con posterioridad, a través de la sentencia ALTER.
create table lectores (
ci integer not null,
apellidos varchar(40) not null,
nombres varchar(40) not null,
domicilio varchar(50),
telefono varchar(20) not null,
primary key(ci)
);
create table prestamos (
ci integer not null,
nro_ejemp integer not null,
fch_préstamo date not null,
fch_vencimiento date not null,
fch_devolucion date,
primary key(ci, nro_ejemp, fch_préstamo),
foreign key(ci) references(lectores),
foreign key(nro_ejemp) references(ejemplares)
);
alter table lectores add estado char(1) not null;
alter table lectores drop estado;
Tipos de datos
- Entre los tipos de datos disponibles para atributos
los numéricos, cadena de caracteres, cadena de bits, fecha y hora.
- Los tipos de datos numéricos incluyen números enteros
de diversos tamaños:
INTEGER, INT, SMALLINT.
También números de reales de diversas precisiones:
FLOAT, REAL, DOUBLE PRECISION
Pueden declararse números con formato, empleando:
DECIMAL(i,j), DEC(i,j), NUMERIC(i,j), MONEY(i,j)
donde i es la cantidad de dígitos decimales y
j es la cantidad de dígitos después del punto decimal.
-
Los tipos de datos de la cadena de caracteres pueden ser de longitud fija:
CHAR(n), CHARACTER(n)
donde n es el número máximo de caracteres, o de longitud variable:
VARCHAR(n), CHAR VARYING(n), CHARACTER VARYING(n)
También, en algunas implementaciones, existe
VARCHAR(n,m)
donde n es el número máximo de caracteres y m es el número mínimo.
- Otros tipos:
- BIT, BLOB, BINARY, para cadenas de bits
- DATE, TIME, DATETIME, para fechas y horas
- TEXT, LONGTEXT, para largas cadenas de caracteres
- TIMESTAMP, para marcas de tiempo
- INTERVAL, para intervalos
Dominios
- Se puede especificar directamente el tipo de datos en cada atributo,
o declarar un dominio:
create domain tipo_CI as integer;
create table lectores (
ci tipo_CI not null,
apellidos varchar(40) not null,
nombres varchar(40) not null,
domicilio varchar(50),
telefono varchar(20) not null,
primary key(ci)
);
Consultas básicas en SQL
Forma genérica:
SELECT <lista de atributos>
FROM <ista de tablas>
WHERE <condición>
Ejemplos:
SELECT ci, apellidos, nombres, domicilio, telefono
FROM lectores
SELECT apellidos, nombres, domicilio, telefono
FROM lectores
WHERE estado != 'B'
Resumen general
SELECT <lista de atributos y de funciones>
FROM <lista de tablas>
[WHERE <condición>]
[GROUP BY <atributo(s) de agrupación>]
[HAVING <condición de agrupación>]
[ORDER BY <lista de atributos>]
SELECT <lista de atributos>
FROM <tabla_1>
[INNER] JOIN <tabla_2>
ON <condición de reunión>
[WHERE <condición de selección>]
SELECT <lista de atributos>
FROM <tabla_1>
LEFT [OUTER] JOIN <tabla_2>
ON <condición de reunión>
[WHERE <condición de selección>]
SELECT <lista_de_atributos_1>
FROM <tabla_1>
[WHERE <condición_de_selección_1>]
UNION
SELECT <lista_de_atributos_2>
FROM <tabla_2>
[WHERE <condición_de_selección_2>]
Funciones agregadas y de agrupación
SELECT COUNT(*)
FROM <tabla>
[WHERE <condición de selección>]
SELECT SUM(columna)
FROM <tabla>
[WHERE <condición de selección>]
SELECT AVG(columna)
FROM <tabla>
[WHERE <condición de selección>]
SELECT MIN(columna)
FROM <tabla>
[WHERE <condición de selección>]
SELECT MAX(columna)
FROM <tabla>
[WHERE <condición de selección>]
Inserción, eliminación, actualización
INSERT INTO <tabla>
[(<lista de columnas>)]
VALUES (<lista de valores>)
DELETE FROM <tabla>
[WHERE <condición>]
UPDATE <tabla>
SET <columna1> = { <valor1> | <columna2> } [, <columna3> = { <valor2> | <columna4> }...]
[WHERE <condición>]
Dependencias funcionales
- El concepto más importante en el diseño de esquemas relacionales es el de
dependencia funcional.
- Una dependencia funcional (DF) es una restricción entre dos conjuntos
de atributos de la base de datos.
- Definimos que X determina funcionalmente a Y
(o que Y depende funcionalmente de X, denotado por X → Y)
en un esquema de relación R, si y sólo si,
siempre que dos tuplas r(R) coincidan en su valor de X,
necesariamente deben coincidir en su
valor de Y.
- Obsérvese que:
- Si una restricción de R dice que no puede haber más de una tupla con un valor X
dado cualquier instancia de relación r(R), es decir, que X es una clave candidata
de R, esto implica que X → Y para cualquier subconjunto de atributos Y de R.
- Si X → Y en R, no nos dice si Y → X en R o no.
- Las dependencias funcionales son propiedades de la semántica o del
significado de los atributos.
- Considerando la relaciones de la aplicación de Biblioteca, a partir de la semántica
de los atributos, se sabe que deben cumplirse las siguientes dependencias funcionales:
-
NRO_LIBRO → TÍTULO
-
CI → { APELLIDOS, NOMBRES, DOMICILIO, TELÉFONO }
-
{ CI, NRO_EJEMP, FCH_PRÉSTAMO } → FCH_DEVOLUCIÓN
-
{ CI, NRO_EJEMP, FCH_PRÉSTAMO } → FCH_VENCIMIENTO
Normalización
- La normalización de los datos puede considerarse como un
proceso de análisis de los esquemas se relación dados basado en sus DF y claves primarias
para alcanzar las propiedades deseables:
- minimizar la redundancia
- minimizar anomalías de inserción, eliminación y actualización
- Los esquemas de relación que no cumplan determinadas condiciones,
las pruebas de formas normales, se descomponen en esquemas de relación
más pequeños que satisfagan dichas pruebas y que de ese modo posean las propiedades
deseables.
- El procedimiento de normalización proporciona a los diseñadores
los siguientes aspectos:
- Un marco formal para analizar los esquemas de relación basándose en sus
claves y en las dependencias funcionales entre sus atributos.
- Una serie de pruebas de formas normales que pueden efectuarse sobre
esquemas de relación individuales de modo que la base de datos relacional pueda
normalizarse hasta el grado deseado.
- El proceso de normalización debe confirmar la existencia de propiedades
adicionales que los esquemas relacionales, en conjunto, deben poseer. Dos de estas
propiedades son:
- La propiedad de reunión sin pérdida o reunión no aditiva,
que garantiza que no se presentará un problema de tuplas espurias.
- La propiedad de conservación de las dependencias, que
asegura que todas las dependencias funcionales estén representadas
en algunas de las relaciones individuales resultantes tras la descomposición.
Repaso
- Si un esquema de relación tiene más de una clave (única), todas
son claves candidatas. Una de las claves candidatas se designa como
clave primaria y las demás se denominan claves secundarias.
- Todo esquema de relación debe tener una clave primaria.
- Un atributo de esquema de relación R se denomina atributo primo
de R si es miembro de alguna clave de R.
- Un atributo es no primo si no es un atributo primo, es decir, si no es miembro
de ninguna clave candidata de R.
Primera Forma Normal (1FN)
- Establece que el dominio de un atributo debe incluir sólo valores atómicos.
- Considérese la siguiente relación:
-
LECTORES (
CI,
APELLIDOS,
NOMBRES,
DOMICILIO,
TELÉFONO,
FCH_PRÉSTAMO_1,
TÍTULO_LIBRO_PRÉST_1,
FCH_VENCIMIENTO_PRÉST_1,
FCH_DEVOLUCIÓN_PRÉST_1,
FCH_PRÉSTAMO_2,
TÍTULO_LIBRO_PRÉST_2,
FCH_VENCIMIENTO_PRÉST_2,
FCH_DEVOLUCIÓN_PRÉST_2,
FCH_PRÉSTAMO_3,
TÍTULO_LIBRO_PRÉST_3,
FCH_VENCIMIENTO_PRÉST_3,
FCH_DEVOLUCIÓN_PRÉST_3,
FCH_PRÉSTAMO_4,
TÍTULO_LIBRO_PRÉST_4,
FCH_VENCIMIENTO_PRÉST_4,
FCH_DEVOLUCIÓN_PRÉST_4,
...,
FCH_PRÉSTAMO_10,
TÍTULO_LIBRO_PRÉST_10,
FCH_VENCIMIENTO_PRÉST_10,
FCH_DEVOLUCIÓN_PRÉST_10
)
- Ventajas:
- Toda la información en una tupla. Una lectura es suficiente.
- Inconvenientes:
- Número absoluto de préstamos...
- La descomposición dará lugar a dos relaciones:
-
LECTORES (
CI,
APELLIDOS,
NOMBRES,
DOMICILIO,
TELÉFONO,
)
-
PRÉSTAMOS (
CI,
FCH_PRÉSTAMO,
TÍTULO_LIBRO,
FCH_VENCIMIENTO,
FCH_DEVOLUCIÓN
)
Segunda Forma Normal (2FN)
- La 2FN se basa en el concepto de dependencia funcional completa:
- Una dependencia funcional X → Y es
una dependencia funcional completa (total), si la eliminación
de cualquier atributo A de X hace que la dependencia deje
de ser válida; es decir, para cualquier atributo A de X,
(X - {A}) no determina funcionalmente a Y.
- Una dependencia funcional X → Y es
una dependencia funcional parcial, si es posible eliminar
un atributo A de X y la dependencia sigue siendo válida.
- La prueba para 2FN incluye la verificación de dependencias funcionales
cuyos atributos del lado izquierdo son parte de la clave primaria. Si la
clave primaria tiene un único atributo, no es en absoluto necesario aplicar la prueba.
- Un esquema de relación R está en 2FN, si todo atributo no primo A
en R depende funcionalmente en forma completa de la clave primaria de R.
- Considérese la siguiente relación:
-
PRÉSTAMOS (
CI,
NRO_LIBRO,
FCH_PRÉSTAMO,
TÍTULO_LIBRO,
EDICIÓN,
NRO_EDIT,
NOMBRE_EDIT,
AÑO,
ISBN,
FCH_VENCIMIENTO,
FCH_DEVOLUCIÓN
)
- Existen atributos que no dependen funcionalmente de toda la clave, sino de parte de ella.
- Deben crearse dos relaciones, para corregir el problema:
-
PRÉSTAMOS (
CI,
NRO_LIBRO,
FCH_PRÉSTAMO,
FCH_VENCIMIENTO,
FCH_DEVOLUCIÓN
)
-
LIBROS (
NRO_LIBRO,
TÍTULO_LIBRO,
EDICIÓN,
NRO_EDIT,
NOMBRE_EDIT,
AÑO,
ISBN
)
Tercera Forma Normal (3FN)
- La tercera forma normal (3FN) se basa en el concepto de dependencia transitiva.
- Una dependencia funcional X → Y en un esquema de relación R
es una dependencia transitiva, si existe un conjunto de atributos Z
que no sea un subconjunto de cualquier clave de R, y se cumplen tanto
X → Z como Z → Y.
- Considérese la siguiente relación:
-
LIBROS (
NRO_LIBRO,
TÍTULO_LIBRO,
EDICIÓN,
NRO_EDIT,
NOMBRE_EDIT,
AÑO,
ISBN
)
- Nótese que el nombre de la editorial (NOMBRE_EDIT) no depende funcionalmente de NRO_LIBRO.
- En realidad:
-
NRO_LIBRO → NRO_EDIT
-
NRO_EDIT → NOMBRE_EDIT
- Por lo tanto, la descomposición creará otra relación:
-
LIBROS (
NRO_LIBRO,
TÍTULO_LIBRO,
EDICIÓN,
NRO_EDIT,
AÑO,
ISBN
)
-
EDITORIALES (
NRO_EDIT,
NOMBRE_EDIT
)
Forma normal de Boyce-Codd (BCNF)
- La forma normal de Boyce-Codd fue propuesta como una forma más simple que la 3FN,
pero resultó más estricta, dado que toda relación que esté en BCNF también está en 3FN;
sin embargo, una relación en 3FN no necesariamente está en BCNF.
- En la práctica, casi todos los esquemas de relación que están en 3FN también están en BCNF.
- Sólo si existe una dependencia X → A en un esquema de relación R, y
X no es una superclave y A es un atributo primo, R estará en 3FN pero
no en BCNF.
Forma normal de Boyce-Codd (BCNF)
Considérese la siguiente relación IMPARTE:
IMPARTE
| ESTUDIANTE |
CURSO |
PROFESOR |
| Relación IMPARTE que está en 3FN pero no en BCNF. |
| Alonso |
Bases de datos |
Núñez |
| Bermúdez |
Bases de datos |
Orozco |
| Bermúdez |
Sistemas Operativos |
Pérez |
| Bermúdez |
Física |
Quesada |
| Cabrera |
Bases de datos |
Núñez |
| Cabrera |
Sistemas Operativos |
Ruiz |
| Domínguez |
Bases de datos |
Sánchez |
| Escobar |
Martínez |
Orozco |
- Con las siguientes dependencias funcionales:
-
DF1: {ESTUDIANTE, CURSO} → PROFESOR
-
DF2: PROFESOR → CURSO
Forma normal de Boyce-Codd (BCNF)
- Obsérvese que
{ESTUDIANTE, CURSO}
es una clave candidata para esta relación y que las dependencias que se muestran
siguen el patrón:
- La descomposición de este esquema de relación en dos esquemas no es
sencilla porque puede descomponerse en uno de los tres pares posibles:
-
{ESTUDIANTE, PROFESOR}
y
{ESTUDIANTE, CURSO}
-
{CURSO, PROFESOR}
y
{CURSO, ESTUDIANTE}
-
{PROFESOR, CURSO}
y
{PROFESOR, ESTUDIANTE}
- Esta tres descomposiciones «pierden» la dependencia funcional DF1.
- La descomposición deseable es la tercera, porque no produce tuplas espurias después de
una reunión.
- En general, una relación que no esté en BCNF debería descomponerse para satisfacer
esta propiedad, al tiempo que posiblemente renuncie a conservar todas las dependencias
funcionales en las relaciones descompuestas, como en el caso del ejemplo precedente.
Dependencias multivaluadas (DMV)
- Las DMV son una consecuencia de la primera forma normal (1FN),
la cual no permite que una tupla tenga un conjunto de valores.
- Si tenemos dos o más atributos multivaluados independientes en el
mismo esquema de relación, nos enfrentaremos al problema de tener
que repetir cada valor de uno de los atributos con cada valor de
otro atributo para que el estado de la relación siga siendo coherente y mantenga
la independencia entre los atributos en cuestión. Esta restricción se especifica
con una dependencia multivaluada.
- Considérese la siguiente relación EMPLEADOS
EMPLEADOS
| NOMBRE_E |
NOMBRE_P |
NOMBRE_D |
|
| Gómez |
X |
Juan |
| Gómez |
Y |
Ana |
| Gómez |
X |
Ana |
| Gómez |
Y |
Juan |
- Una tupla de esta relación representa el hecho de que un empleado cuyo
nombre es NOMBRE_E trabaja en el proyecto NOMBRE_P y tiene varios familiares dependentes,
y los proyectos y dependientes de un empleado son independientes entre sí.
- Para que el estado de la relación siga siendo consistente, deberemos tener tuplas
para representar cada una de las posibles combinaciones entre familiar dependiente
y proyecto de un empleado.
- Esta restricción se especifica como una dependencia multivaluada sobre la relación
EMPLEADO.
- En términos informales, siempre que en la misma relación se mezclan dos relaciones
1:N independientes A:B y A:C, puede surgir una DMV.
DMV. Definición formal.
- En términos formales, una dependencia multivaluada (DMV) X —>> Y
especificada sobre el esquema de relación R, donde X e Y
son subconjuntos de R, especifica la siguiente restricción sobre
cualquier estado de relación r de R: si existen dos tupas
t1 y t2 en r tales que
t1[X] = t2[X], entonces deberían existir dos tuplas
t3 y t4 en r con las siguientes
propiedades, en las que se emplea Z para denotar (R — (X ∪ Y)):
- t3[X] = t4[X] =
t1[X] = t2[X]
- t3[Y] = t1[Y] =
t4[Y] = t2[Y]
- t3[Z] = t2[Z] =
t4[Z] = t1[Z]
- Siempre que se cumple X —>> Y, decimos que X
multidetermina a Y.
- Debido a la simetría de la definición, siempre que
X —>> Y se cumple en R, también se cumple X —>> Z.
Por lo tanto,
X —>> Y implica que X —>> Z, lo que suele denotar como
X —>> Y|Z.
Cuarta forma normal (4FN)
- Se viola cuando una relación tiene dependencias multivaludas no deseables
y puede usarse para identificar esas dependencias descomponer en nuevas relaciones.
- Un esquema de relación está en 4FN respecto a un conjunto de dependencias F
(que incluye dependencias funcionales y dependencias multivaluadas) si, para cada
depedencia multivaluada no trivial X —>> Y en F,
X es una superclave de R.
- La relación EMPLEADO no está en 4FN porque en las DMV no triviales
NOMBRE_E —>> NOMBRE_P y
NOMBRE_E —>> NOMBRE_D, NOMBRE_E no es una superclave de EMPLEADO.
- Descomponemos EMPLEADO en PROYECTOS_EMPLEADO y DEPENDIENTES_EMPLEADO.
Estas dos nuevas relaciones están en 4FN porque
NOMBRE_E —>> NOMBRE_P es una DMV trivial en PROYECTOS_EMPLEADO y
NOMBRE_E —>> NOMBRE_D es una DMV trivial en DEPENDIENTES_EMPLEADO.
- De hecho, no se cumple ninguna DMV no trivial en PROYECTOS_EMPLEADO ni en
DEPENDIENTES_EMPLEADO. Tampoco se cumple ninguna DF en estos dos esquemas
de relación.
Dependencias de reunión
- Una dependencia de reunión DR denotada por
DR (R1, R2, ..., Rn),
especificada sobre el esquema de relación R, especifica una
restricción sobre los estados r de R.
- La restricción establece que todo estado permitido r de R debe tener
una descomposición de reunión sin pérdidas para dar
R1, R2, ..., Rn; esto es:
-
∗ (π1(r),
π2(r), ...,
πn(r)) = r
Quinta forma normal (5FN)
- Un esquema está en quinta forma normal (5FN)
o forma normal de proyección-reunión (FNPR)
respecto a un conjunto F de dependencias funcionales, multivaluadas
y de reunión, si para cada dependencia de reunión no trivial
DR (R1, R2, ..., Rn)
en F, toda Ri es una superclave de R.
Considérese la siguiente relación SUMINISTROS:
Suministros
| NOM_PROVEEDOR |
NOM_COMPONENTE |
NOM_PROYECTO |
| Relación SUMINISTROS que está en 4FN pero no en 5NF. |
| Sánchez |
Perno |
Proyecto X |
| Sánchez |
Tuerca |
Proyecto Y |
| Álvarez |
Perno |
Proyecto Y |
| García |
Tuerca |
Proyecto Z |
| Álvarez |
Clavo |
Proyecto X |
| Álvarez |
Perno |
Proyecto X |
| Sánchez |
Perno |
Proyecto Y |
- Supongamos que siempre se cumple la siguiente restricción adicional:
- Cuando un proveedor s suministra el componente c,
y también un proyecto p utiliza el componente c,
y el proveedor s suministra por lo menos un componente al proyecto p,
entonces el proveedor s suministra el componente c al proyecto p.
- Si se cumple esta restricción, las dos últimas líneas que aparecen recuadradas
deberán existir en cualquier estado permitido de la relación SUMINISTROS,
que también contenga las líneas superiores no destacadas.
Normalizando
La descomposición da lugar a tres relaciones que están en 5FN.
| NOM_PROVEEDOR |
NOM_COMPONENTE |
| Sánchez |
Perno |
| Sánchez |
Tuerca |
| Álvarez |
Perno |
| García |
Tuerca |
| Álvarez |
Clavo |
| NOM_PROVEEDOR |
NOM_PROYECTO |
| Sánchez |
Proyecto X |
| Sánchez |
Proyecto Y |
| Álvarez |
Proyecto Y |
| García |
Proyecto Z |
| Álvarez |
Proyecto X |
| NOM_COMPONENTE |
NOM_PROYECTO |
| Perno |
Proyecto X |
| Tuerca |
Proyecto Y |
| Perno |
Proyecto Y |
| Tuerca |
Proyecto Z |
| Clavo |
Proyecto X |
- Adviértase que una REUNIÓN NATURAL entre dos relaciones cualesquiera de las nuevas,
produciría tuplas espurias, pero la REUNIÓN NATURAL de la tres juntas
no lo hace.
- Es difícil descubrir dependencias de reunión en bases de datos reales con cientos
de atributos y sólo es posible con un grado elevado de intuición respecto a los datos
por parte del diseñador .
Arquitecturas del sistema de base de datos
- Estamos tratando aspectos de implantación de sistemas de bases de datos.
- Distinguimos entre:
- arquitecturas centralizadas, empleadas en los primeros sistemas.
- arquitecturas cliente-servidor, que son las que prevalecen.
Arquitectura de un SGBD centralizado
- Las arquitecturas de los SGBD siguieron tendencias similares a las
de las arquitecturas de sistemas de computadores.
- Las primeras arquitecturas empleaban grandes computadores para proporcionar
el procesamiento principal a todas las funciones del sistema, inclyendo
programas de aplicación de usuario, programas de interfaz de usuario,
así como toda la funcionalidad del SGBD.
- Los usuarios accedían a tales sistemas a través de terminales
de computador que no tenían potencia de procesamiento y sólo ofrecían
capacidades de visualización.
- Todo el procesamiento era realizado en forma remota. La información
se enviaba a las terminales para ser presentada al usuario.
- Las terminales estaban conectadas al computador central a través de varios
tipos de redes de comunicaciones.
- Al bajar los precios del hardware, muchos usuarios sustituyeron
las terminales por computadores personales y estaciones de trabajo.
- Al principio, los sistemas de BD empleaban estos computadores del mismo modo
en que se empleaban las terminales, lo que mantenía una arquitectura centralizada.
- Existía potencia de procesamiento disponible en el usuario, lo que llevó a
arquitecturas SGBD cliente-servidor.
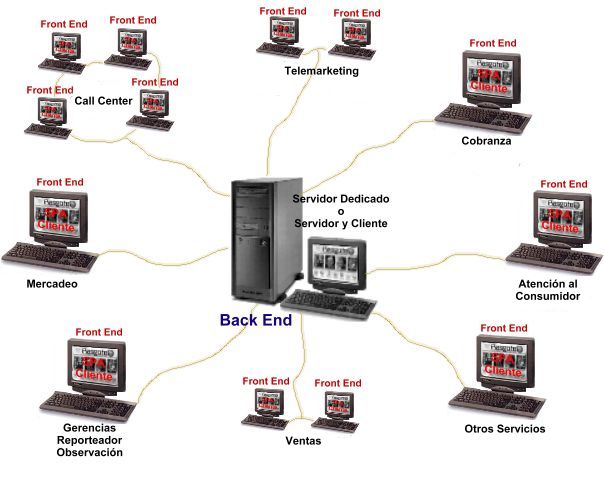
Arquitectura cliente-servidor
- La arquitectura cliente-servidor se creó para manejar los nuevos entornos de
cómputo en los que un gran número de PCs, estaciones de trabajo, servidores de archivos,
impresoras, servidores de bases de datos, servidores web y otros equipos están
interconectados a través de una red.
- La idea es definir máquinas especializadas.
- Por ejemplo es posible conectar un cierto número de pequeñas estaciones de trabajo
o PCs como clientes de un servidor de archivos que mantenga los archivos
de las máquinas cliente.
- Se podría designar otra máquina como servidor de impresoras conectándola a diversas
impresoras; en adelante, todas las solicitudes de impresión de los clientes se enviarán
a esa máquina.
- Los servidores web o servidores de correo electrónico
también se incluyen en la categoría de servidores especializados.
- Las máquinas cliente proporcionan al usuario las interfaces adecuadas para
utilizar estos servidores, así como la potencia de procesamiento local para tratar aplicaciones locales.
- Un cliente en esta estructura es habitualmente una máquina
usuario que proporciona capacidades de interfase de usuario y procesamiento local.
- Cuando un cliente solicita acceso a una funcionalidad adicional, como un acceso a una BD
que no existe en esa máquina, esta le conecta a un servidor que proporciona la funcionalidad
necesaria.
- Un servidor es una máquina que puede proporcionar a las máquinas
cliente servicios tales como impresión, acceso a archivos, o acceso a la BD.
Arquitectura cliente-servidor - Diagrama
Arquitectura cliente-servidor para SGBD
- Un estándar llamado Open Database Connectivity (ODBC) proporciona una interfase
(Aplication Programming Interface: API) que permite a los programas de lado
del cliente llamar al SGBD, siempre que las máquinas tanto cliente como servidor
tengan instalado el software necesario. La mayoría de los proveedores proporcionan
drivers ODBC para sus sistemas.
- También se ha especificado otro estándar relacionado para el lenguaje de programación
JAVA, llamado JDBC. Esto permite a los programas cliente JAVA acceder
al SGBD a través de una interfase estándar.
- El segundo enfoque de la arquitectura cliente-servidor lo siguieron algunos
SGBD orientados a objetos.
- Debido a que muchos de esos sistemas se desarrollaron en la era de la
arquitectura cliente-servidor, el enfoque considerado fue dividir los módulos
de software entre el cliente y el servidor de un modo más integrado.
- Por ejemplo, el nivel servidor podría incluir la parte del software del
SGBD encargada de manejar el almacenamiento de los datos en páginas de disco,
el control de concurrencia y la recuperación local, la utilización de buffers y
el movimiento de páginas de disco a la memoria caché, y otras funciones similares.
- El nivel cliente podría manejar la interfase de usuario,
las funciones del diccionario de datos, la interacción del SGBD con los
compiladores de lenguajes de programación, la optimización de objetos complejos
a partir de los datos en los buffers y otras funciones similares.
- En este enfoque, la interacción cliente-servidor está más firmemente acoplada y
la realizan internamiente los módulos del SGBD, algunos de los cuales residen en el
cliente, y no los usuarios.
- La división exacta de funcionalidades varía de sistema a sistema. En una arquitectura
ciente-servidor, al servidor se le llama servidor de datos, ya que
proporciona a los clientes los datos de las páginas de disco. El propio software
en el lado del cliente puede estructurar los datos de las páginas de disco en objetos
para los programas cliente.
Catálogo de un SGBD relacional
- La información almacenada en el catálogo de un SGBD relacional incluye
descripciones de los nombres de las relaciones, nombres de los atributos,
dominios (tipos de datos) de los atributos, así como descripciones de las
restricciones (claves primarias, claves secundarias, claves foráneas,
nulo/no nulo, y otros tipos de restricciones), vistas, estructuras de
almacenamiento e índices.
- También contiene información de seguridad y autorización; esta
especifica los permisos que tienen los usuarios para acceder a las
relaciones y vistas de la base de datos, y quiénes son los creadores o
propietarios de cada relación.
- En los SGBD relacionales es habitual almacenar el propio catálogo
como relaciones y usar el software del SGBD para consultarlo,
actualizarlo y mantenerlo.
- Esto permite a las rutinas del SGBD y también a los usuarios,
tener acceso a la información almacenada en el catálogo, siempre
que cuenten con la autorización necesaria, empleando el lenguaje
de consulta del SGBD, normalmente SQL.
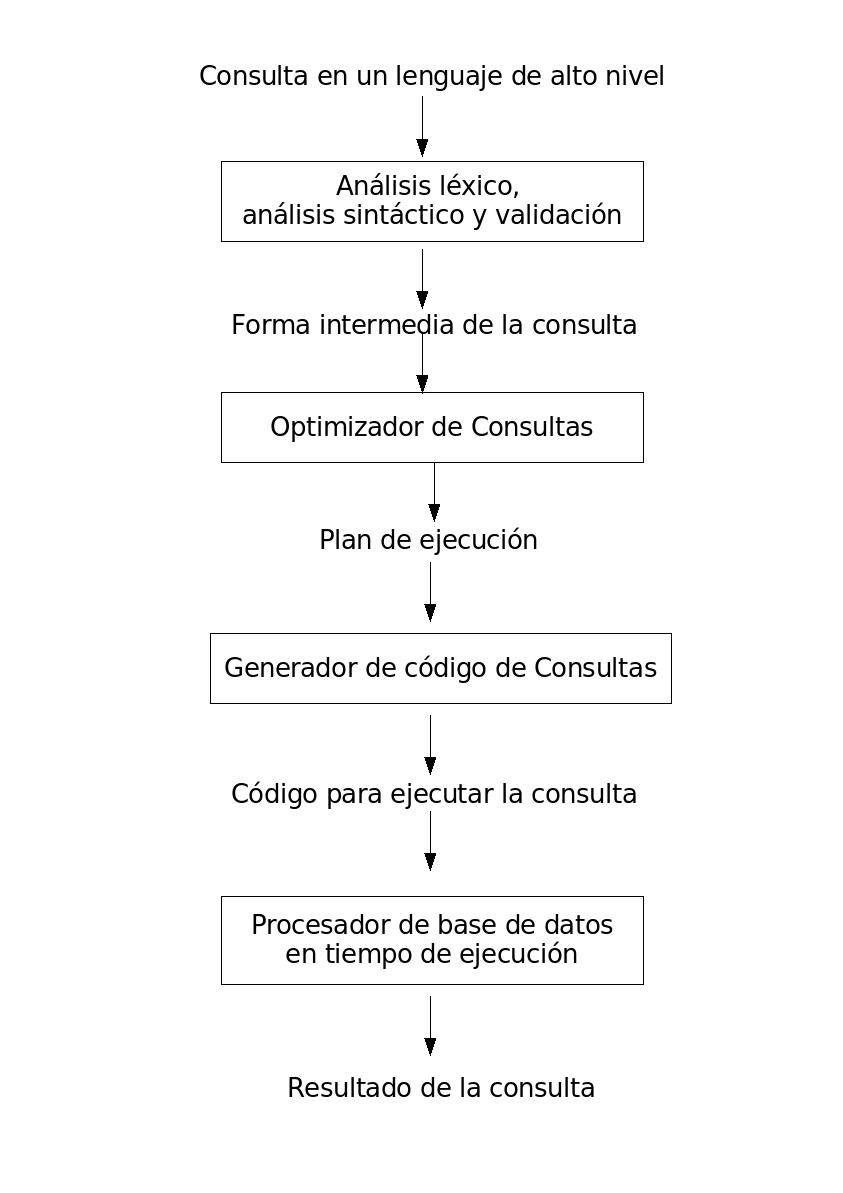
Procesamiento y optimización de consultas
- Una consulta expresada en un lenguaje de alto nivel como SQL,
primero debe pasar por un análisis léxico, un análisis sintáctico y una
validación.
- El analizador léxico identifica los símbolos del lenguaje
(tokens) en el texto de la consulta.
- El analizador sintáctico revisa la sintaxis de la consulta
para determinar si está formulada de acuerdo con las reglas sintácticas (gramaticales)
del lenguaje de consulta.
- El SGBD debe crar una estrategia de ejecución para obtener el resultado de
la consulta a partir de los ficheros internos de la BD.
- Por lo general, una consulta tiene muchas posibles estrategias de ejecución
y el proceso de elegir la más adecuada para procesar una consulta se conoce como
optimización de consultas.
Pasos para procesar una consulta - Diagrama
Pasos para procesar una consulta
- El módulo optimizador de consultas se encarga de producir el plan
de ejecución.
- El generador de código genera el código necesario para ejecutarlo.
- El procesador de base de datos en tiempo de ejecución se encarga de ejecutar
el código de la consulta, sea compilado o interpretado, para producir el resultado
de la consulta. Si se presenta un error durante la ejecución, este procesador genera un
mensaje de error.
- Se puede decir que el término optimización no es exacto porque, en algunos
casos, el plan de ejecución elegido no es la estrategia óptima; es tan sólo una
estrategia razonablemente eficiente para ejecutar la consulta.
- En general, encontrar la mejor estrategia puede consumir demasiado tiempo si la
consulta no es muy simple, y puede requerir información sobre cómo están implementados
los archivos o incluso sobre el contenido de estos; información que tal vez no esté
disponible en el catálogo del SGBD.
- Posiblemente sea más correcta la expresión planificar una estrategia de
ejecución que optimizar consulta.
Transacciones
- El concepto de transacciones proporciona un mecanismo para describir
las unidades lógicas del procesamiento de una BD.
- Los sistemas de procesamiento de transacciones son sistemas con
grandes bases de datos y cientos de usuarios concurrentes que están ejecutando
transaccciones de base de datos. Algunos ejemplos de este tipo de sistemas son
los de reservas, bancos, tarjetas de crédito, cajas de supermercados, etc.
- Son sistemas que requieren una alta disponibilidad y buenos tiempos de
respuesta para cientos de usuarios concurrentes.
- Una transacción es una unidad lógica de procesamiento de la BD que incluye una o más
operaciones de acceso a la BD, que pueden ser de inserción, eliminación, modificación o
recuperación.
- Las operaciones de la BD que forman una transacción pueden estar insertadas
dentro de un programa de aplicación o pueden especificarse interactivamente a través de un
lenguaje de consulta de alto nivel como SQL.
- Una forma de especificar los límites de la transacción es mediante las sentencias
begin transaction y end transaction, en un programa
de aplicación; en ese caso, todas las operaciones de acceso a la BD entre ambas, se
consideran parte de una misma transacción.
- Un programa de aplicación sencillo puede contener más de una transacción si contiene
varios delimitadores de transacción. Si las operaciones de la base de datos en la transacción
no actualizan la base de datos, sino que sólo recuperan datos, la transacción se denomina
transacción de sólo lectura.
Control de concurrencia
- Pueden surgir varios problemas cuando las transacciones concurrentes se
ejecutan de manera no controlada.
- Supongamos una BD sencilla de reservas en una línea aérea. Cada registro incluye
el número de asientos reservados por cada vuelo como elemento de información
con nombre, entre otras informaciones.
- Supongamos la transferencia de N reservas de un vuelo, cuyo
número de asientos reservados está almacenado en el elemento de la BD llamado
X, a otro vuelo, cuyo número de asientos reservados está almacenado en
el elemento de la BD llamado Y.
Problema de la actualización perdida
- Ocurre cuando las transacciones que tienen acceso a los mismos
elementos de la BD tienen sus operaciones intercaladas de modo que
hacen incorrecto el valor de algún elemento.
| T1 |
T2 |
| read_item(X); |
|
| X := X - N; |
|
| |
read_item(X); |
| |
X := X + M; |
| write_item(X); |
|
| read_item(Y); |
|
|
write_item(X); |
| Y := Y + N; |
|
| write_item(Y); |
|
El elemento X tienen un valor incorrecto porque la actualización
realizada por T1 se ha sobrescrito y es como si no hubiera tenido efecto.
Problema de la actualización temporal (lectura sucia)
- Ocurre cuando una transacción actualiza un elemento de la BD
y luego la transacción falla por alguna razón.
- Otra transacción tiene acceso al elemento actualizado antes de que se restaure
a su valor original.
| T1 |
T2 |
| read_item(X); | |
| X = X - N; | |
| write_item(X); | |
| | |
| | read_item(X); |
| | X := X + M; |
| | write_item(X); |
| read_item(Y); | |
La transacción T1 falla y debe restaurar X
a su antiguo valor; mientras tanto T2 ha leído el
valor temporal incorrecto de X.
Problema del resumen incorrecto
- Si una transacción está calculando una función agregada de resumen
sobre varios registros mientras otras transacciones están actualizando
algunos de ellos, puede ser que la función agregada calcule algunos
valores antes de que se actualicen y otros después de actualizarse.
- Supongamos que una transacción T3 está calculando el número
total de reservas de todos los vuelos; mientras tanto se está ejecutando
la transacción T1.
- Si ocurre la intercalación de operaciones que se muestra en el
siguiente esquema, el resultado de T3 será erróneo por una cantidad
N porque T3 lee el valor de X después de que se
la han restado N asientos pero lee el valor de Y antes de que se le
sumen esos N asientos.
| T1 |
T3 |
| | suma:=0;
|
| | read_item(A);
|
| | suma:=suma+A;
|
| | .
|
| | .
|
| | .
|
| read_item(X) |
|
| X:=X-N; |
|
| write_item(X); |
|
| | read_item(X);
|
| | suma:=suma+X;
|
| | read_item(Y);
|
| | suma:=suma+Y;
|
| read_item(Y); |
|
| Y:=Y+N; |
|
| write_item(Y); |
|
T3 lee X después de restarle N
y lee Y antes de sumársele N, así que el resultado es
un resumen incorrecto (discrepancia de N).
Lectura no repetible
- Otro problema que puede presentarse es el de la lectura no repetible,
en el que una transacción T lee un elemento dos veces y otra transacción T'
modifica el elemento entre las dos lecturas.
- Así T recibe diferentes valores en sus dos lecturas del mismo elemento.
- Esto puede ocurrir si, por ejemplo, durante una transacción de reserva de líneas aéreas,
un cliente está preguntando sobre la disponibilidad de asientos en varios vuelos.
Cuando el cliente se decide por un vuelo concreto, entonces la transacción lee por
segunda vez el número de asientos de dicho vuelo antes de completar la reserva.
Por qué es necesaria la recuperación
- Siempre que se introduce una transacción a un SGBD para ejecutarla,
el sistema tiene que asegurarse de que:
- todas las operaciones de la transacción se superen con éxito y su
efecto quede registrado permanentemente en la BD, o que,
- la transacción no tenga efecto alguno sobre la BD ni sobre cualquier otra transacción.
- El SGBD no debe permitir que se apliqen a la base de datos algunas operaciones
de la transacción T y otras operaciones de T no lo hagan. Esto puede
suceder si una transacción falla después de ejecutar algunas de
sus operaciones, pero antes de ejecutarlas todas.
- Tipos de fallos:
- Un fallo del computador (caída del sistema): durante la ejecución de una
transacción se produce un error de hardware, software o
de red. Los fallos del hardware normalmente son fallos de los medios,
por ejemplo un fallo de la memoria principal.
- Un error de la transacción o del sistema: alguna operación de la
transacción puede hacer que esta falle, por ejemplo un desbordamiento (overflow)
de enteros o una división entre cero. También puede haber un fallo de transacción
debido a valores erróneos de los parámetros o a un error lógico de programación.
Además, puede suceder que el usuario interrumpa a propósito la transacción durante
su ejecución.
- Errores locales o condiciones de excepción detectadas por la transacción:
durante la ejecución de transacciones pueden presentarse ciertas condiciones
que requieran la cancelación de la transacción. Por ejemplo, puede que no se encuentren
los datos para la transacción.
- Imposición de control de concurrencia: el método de control de concurrencia
puede decidir que se aborte la transacción, para reiniciarla después, porque viola
la seriabilidad o porque varias transacciones se encuentran un un estado de
abrazo mortal (deadlock).
- Fallo del disco: algunos bloque de disco pueden perder sus datos
por un mal funcionamiento de lectura o de escritura o por un fallo de una cabeza de
lectura/escritura. Esto puede suceder durante una operación de lectura o de escritura
de la transacción.
- Problemas físicos y catástrofes: esto se refiere a una interminable
lista de problemas que incluyen interrupción del suministro de energía o aire
acondicionado, incendio, robo, sabotaje, sobreescritura de discos o cintas por error
o porque el operador haya montado una cinta equivocada.
- Los fallos del tipo 1,2 3, y 4 son más comunes que los del tipo 5 y 6. Siempre que
ocurre un fallo del tipo 1 al 4, el sistema debe mantener suficiente información
para recuperarse del fallo.
- Los fallos de disco o los catastróficos del tipo 5 y 6 no ocurren con frecuencia;
si se dan, la recuperación es una tarea bastante complicada.
Estados de transacciones
- Una transacción es una unidad atómica de trabajo que se realiza por completo o bien no se efectúa
en absoluto. Para fines de recuperación el sistema necesita mantenerse al tanto de cuándo la
transacción se inicia, termina y se confirma o aborta. Entonces, el gestor de recuperación se
mantiene al tanto de las siguientes operaciones:
- BEGIN_TRANSACTION (inicio_de_transacción): marca el principio de la
ejecución de la transacción.
- READ (leer) o WRITE (escribir): especifican operaciones de lectura
o escritura de elementos de la BD que se ejcutan como parte de la transacción.
- END_TRANSACTION (fin_de_transacción): especifica que las operaciones
de LEER o ESCRIBIR de la trasacción han terminado y marca el fin
de la ejecución de la transacción. Sin embargo, en este punto puede ser necesario
verificar si los cambios introducidos por la transacción se pueden aplicar
permanentemente a la BD (confirmar) o si la transacción debe abortarse porque
viola la seriabilidad o por alguna otra razón.
- COMMIT_TRANSACTION (confirmar_transacción): señala qaue la transacción
terminó con éxito y que cualquier cambio (actualizaciones)
ejecutado por ella se puede confirmar sin peligro en la base de
datos y que no se deshará.
- ROLLBACK (restaurar) o ABORT (abortar): indican que la transacción
terminó sin éxito y que cualquier cambio o efecto que pueda
haberse aplicado a la base de datos se debe deshacer.
Diario del Sistema (Log)
- Para poder recuperar fallos de transacciones, el sistema mantiene un diario
(log) que sigue la pista de todas la operaciones de transacciones que afectan los
valores de la BD. Esta información es necesaria para realizar la recuperación en caso de fallos.
- El diario se mantiene en disco, de modo que no le afecta ningún tipo de fallo, más que los
del disco y los llamados "catastróficos".
- Periódicamente se realiza una copia de seguridad del diario en cinta para protegerse
de fallos catastróficos.
- Mencionaremos los tipos de entradas, denominados registros del diario que
se escriben en él, y la acción que realiza cada una de esas entradas. T
se refiere a un identificador de transacción único que el sistema
genera automáticamente y que sirve para identificar cada transacción:
- [start_transaction, T]: indica que se ha iniciado la ejecución
de la transacción T.
- [write_item, T, X, valor_anterior, valor_nuevo]: indica que la
transacción T ha cambiado el valor del elemento de base de datos X
del valor_anterior al valor_nuevo.
- [read_item, T, X]: registra que la transacción t leyó
el valor del elemento X de la base de datos.
- [commit, T]: indica que la transacción T terminó con
éxito y establece que su efecto se puede confirmar (registrar permanentemente) en la
base de datos.
- [abort, T]: indica que se abortó la transacción T.
Diario del Sistema (Log)
- Dado que el diario contiene un registro por cada operación WRITE
que altere el valor de algún elemento de la base de datos, es posible
deshacer el efecto de estas operaciones WRITE de una transacción
T rastreando hacia atrás en el diario e iniciando todos los elementos
alterados con una operación WRITE de T con su valor_anterior.
- También puede ser necesario rehacer las operaciones de una transacción
si todas sus actualizaciones se han grabado en el diario pero el fallo ocurrió
antes de que estemos seguros de que todos esos valores_nuevos se han
escrito permanentemente en la actual base de datos en disco.
- Para rehacer el efecto
de las operaciones WRITE de una transacción T debe rastrearse
hacia adelante en el diario y cambiar todos los elementos modificados por una función
ESCRIBIR de T a su valor_nuevo.
Punto de confirmación de una transacción
- Una transacción T llega a un punto de confirmación
cuando todas sus operaciones que tienen acceso a la base de datos
se han ejecutado con éxito y el efecto de todas estas operaciones
se ha registrado en el diario.
- Más allá del punto de confirmación, se dice que la transacción está
confirmada y se supone que su efecto se registró
permanentemente en la base de datos.
- En ese momento, la transacción escribe un registro [commit, T]
en el diario.
- Si ocurre un fallo del sistema, buscamos hacia atrás en el diario todas
las transacciones T que han escrito una entrada [start_transaction, T]
en el diario pero no han escrito todavía su entrada [commit, T];
es posible que durante el proceso de recuperación haya que restaurar (rollback) estas
transacciones para deshacer su efecto sobre la base de datos.
- Las transacciones que ya escribieron su registro de confirmación en el diario
también deberán haber registrado en él todas sus operaciones WRITE y por tanto
su efecto sobre la base de datos puede rehacerse a partir de los registros del diario.
Punto de confirmación: forzar la escritura
- Obsérvese que el archivo del diario debe mantenerse en disco. La actualización
de un archivo en disco implica copiar el bloque apropiado del archivo del disco
a un búfer de la memoria principal, actualizar el búfer de la memoria principal
y copiar el búfer en el disco.
- Con frecuencia se mantiene uno o más bloques del archivo diario en los búfers
de la memoria principal hasta que se llena de entradas y luego se escribe una sola vez
en el disco, en vez de escribirlo cada vez que se añade una entrada. Esto ahorra
el gasto extra de escribir varias veces en disco el mismo bloque de archivo diario.
- Cuando se cae el sistema, solo las entradas del diario que se han escrito en disco
se considera que están en el proceso de recuperación, porque puede haberse perdido el
contenido de la memoria principal. Por ello, antes de que una transacción llegue
a su punto de confirmación, cualquier porción del diario que no se haya escrito en
el disco todavía, se deberá grabar.
- Este proceso se denomina forzar la escritura del archivo diario
antes de confirmar una transacción.
Propiedades deseables en las transacciones
- Las transacciones atómicas deben poseer varias propiedades. Estas se conocen
como propiedades ACID, por sus inciales en inglés, y su cumplimiento
debe estar asegurado por los métodos de control de concurrencia y de recuperación
del SGBD. Las propiedades ACID son:
- Atomicidad: una transacción es una unidad atómica de
procesamiento; o bien se realiza por completo o no se realiza en absoluto.
- Conservación de la consistencia: una transacción conserva
la consistencia si su ejecución completa lleva una base de datos de un estado
consistente a otro.
- Aislamiento (en inglés isolation): una transacción
debería parecer que se está ejecutando de forma aislada de las demás transacciones.
Es decir, la ejecución de una transacción no debería interferir con otras
transacciones que se ejecuten concurrentemente.
- Durabilidad o permanencia: los cambios aplicados a la
base de datos por una transacción confirmada deben perdurar en la base de datos.
Estos cambios no deben perderse por un fallo posterior.
Planes y recuperabilidad
- Cuando varias transacciones se ejecutan de manera concurrente e intercalada, el orden de
ejecución de sus operaciones constituye lo que se conoce como plan (o
historia).
- Un plan (o historia) P de n
transacciones T1, T2, ..., Tn es un ordenamiento
para las operaciones de las transacciones sujeto a la restricción de que, para cada
transacción Ti que participe en P, las operaciones de
Ti en P deben aparecer en el mismo orden en que ocurren en
Ti.
- Cabe señalar, sin embargo, que las operaciones de otras transacciones Tj,
se pueden intercalar con las operaciones de Ti en P.
- Por ahora consideramos que el orden de las operaciones en P
es un ordenamiento total, aunque en teoría es posible
manejar planes cuyas operaciones formen órdenes parciales.
- Para el objetivo de recuparación y control de concurrencia,
nuestro interés principal está en las operaciones de las transacciones
read_item (leer_elemento) y write_item (escribir_elemento), así como
en las operaciones commit (confirmar) y abort (abortar).
- Una notación abrevidada para describir un plan usa los símbolos
r, w, c y a para las operaciones read_item,
write_item, commit y abort,
respectivamente, añadiendo como subíndice el identificador de la
transacción (número de la transacción) para cada operación del plan.
En esta notación, el elemento X de la base de datos que se lee o escribe,
sigue a las operaciones r y w entre paréntesis.
Planes (historias) de transacciones
Consideremos la siguiente figura, usada en el ejemplo de la actualización perdida.
el plan, que llamaremos Pa se puede escribir como sigue, añadidas las
operaciones de confirmación:
| T1 |
T2 |
| read_item(X); |
|
| X := X - N; |
|
| |
read_item(X); |
| |
X := X + M; |
| write_item(X); |
|
| read_item(Y); |
|
|
write_item(X); |
| Y := Y + N; |
|
| write_item(Y); |
|
El plan para esta figura, que llamaremos Pa se puede escribir como sigue,
después de añadidas las operaciones de confirmación:
-
Pa:
r1(X);
r2(X);
w1(X);
r1(Y);
w2(X);
w1(Y);
Planes (historias) de transacciones
Considérese ahora la figura del ejemplo
de lectura sucia.
| T1 |
T2 |
| read_item(X); | |
| X = X - N; | |
| write_item(X); | |
| | |
| | read_item(X); |
| | X := X + M; |
| | write_item(X); |
| read_item(Y); | |
De manera similar, el plan de esta figura, que llamaremos Pb se puede
escribir como sigue, suponiendo que la transacción T1 abortó después de
su operación read_item(Y):
-
Pb:
r1(X);
w1(X);
r2(X);
w2(X);
r1(Y);
a1;
Operaciones en conflicto
- Se dice que dos operaciones de un plan están en conflicto si satisfacen
las tres siguientes condiciones:
- pertenecen a diferentes transacciones
- tienen acceso al mismo elemento X
- al menos una de las dos operaciones es write_item(X)
- Por ejemplo en Pa las operaciones r1(X) y
w2(X)
están en conflicto, lo mismo que
r2(X) y w1(X),
y que
w1(X) y w2(X).
- Sin embargo, las operaciones r1(X) y r2(X)
porque ambas son operaciones de lectura.
- Y las operaciones w2(X) y w1(Y) tampoco están en conflicto,
porque operan sobre diferentes elementos de datos, X e Y.
- Y las operaciones r1(X) y w1(X) no están en conflicto
porque pertenecen a la misma transacción.
Plan completo
- Se dice que un plan P de n
transacciones T1, T2, ..., Tn es un
plan completo si se cumplen las siguientes condiciones:
- Las operaciones de P son exactamente las operaciones
de T1, T2, ..., Tn
incluidas una operación de confirmar (commit) o de abortar (abort)
como última operación de cada transacción en el plan.
- Para cualquier plan de operaciones de la misma transacción Ti, su orden
de aparición en P es el mismo que su orden de aparición en Ti.
- Para dos operaciones cualesquiera en conflicto, una de ellas debe ocurrir antes
que la otra en el plan. Teóricamente no es necesario determinar un orden entre
pares de operaciones que no están con conflicto.
- La última condición (3) permite que dos operaciones que no están en conflicto
ocurran en el plan sin definir cuál lo hace primero, dando lugar a la definición de un plan
como un orden parcial de las operaciones de n transacciones.
En la práctica, la mayoría de los planes tienen un orden total de las operaciones.
Si se emplea procesamiento en paralelo, es teóricamente posible tener planes con
operaciones parcialmente ordenadas que no estén en conflicto.
- Sin perjuicio de lo dicho, se debe especificar un orden total en el plan
para cualquier par de operaciones en conflicto (condición 3) y para cualquier
par de operaciones en la misma transacción (condición 2). La condición 1 simplemente
dice que todas las operaciones de las transacciones deben aparecen en el plan
completo.
- Puesto que toda transacción ha sido confirmada o abortada, un plan completo
nunca contendrá transacciones activas al final del plan.
- En general, es difícil encontrar planes completos en un sistema de procesamiento
de transacciones, porque continuamente se están introduciendo nuevas transacciones
en el sistema.
- Por eso conviene definir el concepto de proyección confirmada C(P) en un plan
P, que incluye sólo las operaciones de P que pertenecen a transacciones confirmadas;
es decir, transacciones Ti, cuya operación de confirmación Ci
está en P.
Caracterización de planes basados en su recuperabilidad
- En algunos planes resulta fácil recuperarse de fallos de transacciones,
pero en otros dicho proceso puede ser bastante complicado.
- Por ello, es importante caracterizar los tipos de planes en los cuales
es posible la recuperación, así como aquellos en los que la recuperación
es relativamente simple.
- Estas caracterizaciones realmente no proporcionan un algoritmo de
recuperacion sino que únicamente intentan caracterizar teóricamente los
diferentes tipos de planes.
- En primer lugar, nos gustaría estar seguros de que, una vez que se ha
confirmado una transacción T, nunca será necesario deshacerla (rollback)
- Los planes que teóricamente satisfacen este criterio se denominan planes recuperables
y aquellos que no lo satisfacen de denominan no recuperables y por lo tanto
no se deben permitir.
- Un plan P es recuperable si ninguna transacción T de P se confirma
antes de que se hayan confirmado todas las transacciones T' que han escrito
un elemento que T lee.
- Una transacción T lee de una transacción T' de un plan P
si T' escribe primero algún elemento X y luego T lo lee.
- Además T' no deberá haber sido abortada antes de que T lea el elemento X,
y no debería haber transacciones que escriban X después de que T' lo haya
escrito y antes de que T lo lea, a menos que estas transacciones, de existir,
se hayan abortado antes de que T lea X.
- Los planes recuperables requieren un complejo proceso de recuperación,
pero si se guarda la información necesaria en el diario (log), se puede idear
un algoritmo de recuperación.
Transacciones en SQL
- A toda transacción se le atribuyen ciertas características que se
especifican con la sentencia SET TRANSACTION de SQL2.
- Estas características son el modo de accso, el tamaño del área
de diagnóstico y el nivel de aislamiento.
- El modo de acceso puede especificarse como READ ONLY (sólo lectura)
o READ WRITE (leer y escribir). El valor por omisión es READ WRITE, a menos
que se especifique el nivel de aislamiento de lectura no confirmada
(READ UNCOMMITTED), en cuyo caso se supone READ ONLY. Un modo de
READ WRITE permite que se ejecuten instrucciones de modificar, insertar, borrar
y crear. Un modo de READ ONLY se usa solamente para recuperación de datos.
- La opción de tamaño del área de diagnóstico, DIAGNOSTIC SIZE n,
especifica un valor entero n que indica el número de condiciones que se pueden tomar
simultáneamente en el área de diagnóstico. Estas condiciones suministran al usuario
información de feedback (errores o excepciones) sobre las setencias SQL ejecutadas
más recientemente.
- La opción del nivel de aislamiento se especifica utilizando la sentencia
ISOLATION LEVEL <aislamiento>, donde el valor para <aislamiento> puede ser
READ UNCOMMITTED (lectura no confirmada), REPEATABLE READ (lectura repetible),
o SERIALIZABLE. El nivel de aislamiento por omisión es SERIALIZABLE, aunque en
algunos sistemas la opción predeterminada es READ COMMITTED.
- El uso del término SERIALIZABLE aquí, se basa en no permitir violaciones
que causen lecturas sucias, lecturas no repetibles ni fantasmas, y por tanto no es
idéntico a a definición que se dio anteriormente de seriabilidad.
Nivel de aislamiento (Isolation Level)
- Si una transacción se ejecuta en un nivel de asilamiento más bajo que SERIALIZABLE,
entonces pueden ocurrir una o más de las siguientes tres violaciones:
- Lectura sucia: una transacción T1 puede leer la actualización
de la transacción T2, que todavía no se ha confirmado.
Si T2 falla y se aborta, entonces T1
habría leído un valor que no existe y es incorrecto.
- Lectura no repetible: una transacción T1 puede leer
un determinado valor de una tabla.
Si una transacción T2 actualiza más tarde dicho valor
y T1 lee de nuevo el valor, T1
verá un valor diferente.
- Fantasmas: una transacción T1 puede leer
un conunto de filas de una tabla, quizá basadas en una condición
especificada en una cláusula WHERE de SQL.
Supóngase que una transacción T2 inserta una nueva fila
que también satisface la condición de la cláusula WHERE
usada en T1, en la tabla utilizada por T1.
Si T1 se repite, entonces T1 verá un fantasma,
una fila que previamente no existía.
Violaciones posibles basadas en los niveles de aislamiento
Violaciones posibles basadas en los niveles de aislamiento definidos en SQL
| Nivel de aislamiento | Tipo de Violación |
|---|
| Lectura sucia | Lectura no repetible | Fantasma |
| LECTURA NO CONFIRMADA | Sí | Sí | Sí |
| LECTURA CONFIRMADA | No | Sí | Sí |
| LECTURA REPETIBLE | No | No | Sí |
| SERIALIZABLE | No | No | No |
Bibliografía
Sanders DH; (1983). Informática: presente y futuro. 1a. ed., McGraw-Hill, México.
Batini, Ceri, Navathe.; (1994).
Diseño Conceptual de Bases de Datos. Un enfoque de Entidades/Interrelaciones.
Addison Wesley/Diaz De Santos.
Date C.J.; (2003). An introduction to Database Systems.
8a. ed., Addison Wesley.
Elmasri R, Navathe S.; (2005).
Fundamentos de Sistemas de Bases de Datos. 3a. ed., Pearson Educación, Madrid.
Korth, Silberschatz, Sudarshan.; ( 2006).
Fundamentos de Bases de Datos. 5a. ed., Mc Graw Hill.
Ullman Jeffrey D., Widom J. (1999).
Introducción a los sistemas de Bases de Datos. 1a. ed., Pearson.